More Noteworthy Aspects of DeepSeek 3FS
More Noteworthy Aspects of DeepSeek 3FS
Recently, DeepSeek has emerged, not only reducing the cost of large language models by several times [1], but also open-sourcing the entire AI infrastructure, the models, and the operational costs. Among them, 3FS demonstrates what an AI-oriented storage system looks like, deeply integrating and optimizing with DeepSeek’s AI infrastructure [4].
Many experts on the internet have already provided comprehensive interpretations of 3FS:
-
ByteDance: https://mp.weixin.qq.com/s/X60PsEPeFsb-ZPKATMrWrA
-
StorageScale: https://mp.weixin.qq.com/s/sPkqOdVA3qBAUiMQltveoQ
Based on this, I would like to list some additional points that I find interesting and have thoughts about.
Prior series:
P Specification
A major challenge in distributed systems is correctness. In recent years, formal verification has been increasingly adopted in storage systems, with common languages including TLA+ [6] and P Spec [7]. TLA+, promoted by the renowned Lamport, is close to mathematical logic and supports correctness proofs. In contrast, the language of P Spec revolves around state machines, with a syntax that is much more programmer-friendly, focusing on state iteration verification and optimizing the search of the state space [8].
Who is using P Spec? Typical examples include Microsoft’s USB3 [9], IoT [10], and Async Event Handling [11]; DeepSeek’s 3FS [5]. Who is using TLA+? Typical examples include AWS’s DynamoDB [12], S3 [13], EBS [12]; MongoDB’s replication protocol [14], TiDB [15], and CockroachDB [16].
In 3FS, P Spec is used to model DataStorage and verify the correctness of the replication protocol, such as ensuring all writes must complete, version numbers must increment, and all replicas must be updated, among other things. P Spec is also used to model RDMASocket, verifying that all pending data must be processed, buffer usage must not exceed limits, and no duplicate sends are allowed, etc.
On the other hand, regarding correctness, 3FS uses Rust to implement the storage engine [17]. The Rust language has built-in strict memory safety mechanisms (Ownership), incurring costs at compile time rather than at runtime. Even setting aside these aspects, using Rust as one would use C/C++ makes the language much more modern. Rust is increasingly being used to rewrite lower-level systems, such as AWS S3 [13] and the Linux kernel [18] (Non-trivial).
Metadata Management
One major challenge of distributed file systems is managing the vast inode and dentry metadata, while another significant challenge is implementing distributed transactions for rename, rmdir, and mv operations. Early systems, such as HopsFS [19], implemented transactions using more complex methods; whereas Facebook (Meta) Tectonic [20] simply does not support cross-shard transactions.
3FS has simply solved these problems by reusing Apple FoundationDB [21], which supports distributed transactions. As an open-source, horizontally scalable, and distributed transaction-supporting KV database, there are not many choices, and FoundationDB may be the only option. Moreover, FoundationDB has been validated by large companies, and the open-source support and documentation are also quite good [22]. In contrast, RocksDB is also very commonly used, but it is often used to address single-node needs.
In distributed file systems, using a database to manage metadata has been a trend in recent years. 3FS uses FoundationDB to manage the cluster’s metadata and RocksDB to manage the metadata of storage nodes. Similarly, Ceph BlueStore [23] also uses RocksDB to manage the metadata of storage nodes, Tectonic uses ZippyDB to manage the cluster’s metadata [20], and JuiceFS supports options like PostgreSQL, Redis, TiKV, etc., to manage the cluster’s metadata [24].

(The image is from ByteDance’s 3FS interpretation, link can be found at the beginning of the article)
FUSE user space file system
The file system’s efforts to place everything into user space are relentless. At the beginning of the article, there is a more profound and detailed interpretation of FUSE in the 3FS article about XSKY.
This is not just for performance; debugging the kernel becomes more difficult, making it hard to upgrade and deploy without interference. 3FS cleverly integrates the design of io_uring into FUSE to break through its performance and copying limitations, and connects to RDMA for sending and receiving. The new API is called USRBIO [25].

(The image is from [35])
Write process and copy protocol
3FS adopts Chain Replication, which is a common write protocol focused on simplicity. Another commonly used protocol is Quorum Write, often seen in databases like TiDB [27], PolarDB [28], etc. It is curious why 3FS does not use star replication (which is compatible with Quorum Write). Chain Replication can introduce additional write latency due to the number of hops between nodes, while all-flash scenarios often use star replication.
The CRAQ adopted by 3FS focuses on allowing data to be read from replicas, noting that the primary replica may be writing data. The data from the replicas may be at most one version behind, and clients need to relax consistency constraints. In contrast, Ceph often requires that only the primary replica can read data, which sacrifices the bandwidth of replicas for strong consistency. A noteworthy example is that AWS S3 implements strong consistency based on Quorum Write/Read [29].
On the other hand, if the system is append-only, allowing reads from all replicas under strong consistency does not seem so difficult, although file systems always allow in-place modifications. Despite this, the storage engine of 3FS is Copy-on-Write (COW).

It seems that 3FS does not have many optimizations for the write path, especially regarding latency. For example, its GitHub page [2] only published read throughput without write metrics, and the write path heavily uses locks and synchronous I/O [26], unlike the read path and network I/O which are sufficiently coroutine-optimized. This can be explained by the use cases of AI storage, where data loading, KVCache, and training set reading are all read-heavy scenarios, and training set reading even requires small random reads (FFRecord). Although Checkpoint is a rewrite scenario, it is mostly for batch writing.
Additionally, regarding Checkpoint, the DeepSeek infrastructure paper [4] mentions that it occurs every 5 minutes, with each node achieving a write speed of 10 GB/s (180 nodes), completing the entire Checkpoint in a matter of seconds. Furthermore, the 3FS design document [2] states that there are 3 replicas, but the paper [4] describes 2 replicas, as seen in VI-B2: “The total 2880 NVMe SSDs provide over 20PiB storage space with a mirror data redundancy.”
The paper also mentions that 3FS-KV, message queues, and object storage are built on top of 3FS. At the beginning of the article, Andy provides a more detailed introduction to 3FS in his interpretation article. 3FS-KV is used for KVCache, message queues are used for inter-module instruction communication, and object storage is used for storing images, videos, documents, etc. This approach is similar to VAST DATA [32], Ceph [31], and Azure Storage [30], building diverse services on a unified storage platform.
Data Placement
How does 3FS decide where to store data? First, files are split into equal-length chunks for storage, and the chunks are distributed as much as possible. The inode of the file can be used to find which Chain Table the file uses, as well as the random number seed. Together with the Chunk ID of the data block, these can locate the replication chain in the Chain Table. The replication chain contains the targets of the 3 replicas, which correspond to the SSDs of the storage nodes.
It is worth noting that an SSD is divided into multiple Targets, and the “replicas” of 3 copies refer to Targets, rather than the common server nodes. This is likely to further split the extremely high bandwidth that a single SSD can provide. On the other hand, arranging the Chain Table requires consideration of data balance and allowing as many nodes as possible to participate in recovery after a node failure. This is regarded as a Balanced Incomplete Block Design [2] problem, which can be generated by the optimizer during deployment [33].

(The image is from the 3FS design document [2])
Network
The DeepSeek infrastructure paper [4] describes its network construction. The network is divided into 2 Zones, using InfiniBand and a 2-layer Fat-tree architecture. Each storage node is equipped with dual IB network cards, each connecting to one Zone to share storage services across the Zones.
For flow control (QoS), the network uses InfiniBand Service Level (SL) and maps it to Virtual Lane (VL). Different VLs do not interfere with each other. The network uses static routing, and this direction seems similar to Google Orion SDN [34]. The SDN controller has a global view and, after periodically refreshing optimal decisions, issues routing configurations to the switches. NCCL has additional optimizations, such as NUMA affinity for IB NIC and GPU, and PCIe Relaxed Ordering.
3FS implements a congestion control mechanism called Request-to-Send to avoid Incast. Before transmitting data, the storage node needs to ask the client for permission, and the client limits the number of concurrent requests.
It is worth noting that 3FS makes extensive use of One-sided RDMA. For example, when the client writes data, it is completed through an RDMA Read initiated by the storage node; whereas when the client reads data, it is done through an RDMA Write initiated by the storage node.

(The image is from [4])
The paper [4] mentions that DeepSeek will explore replacing InfiniBand with RoCE in the future to reduce costs. The new nodes will be equipped with one-to-one network cards with GPUs. The number of network cards will double or more. Continuing the previous 2-zone architecture, the network cards in the same node will each connect to a 2-layer Fat-tree Plane.
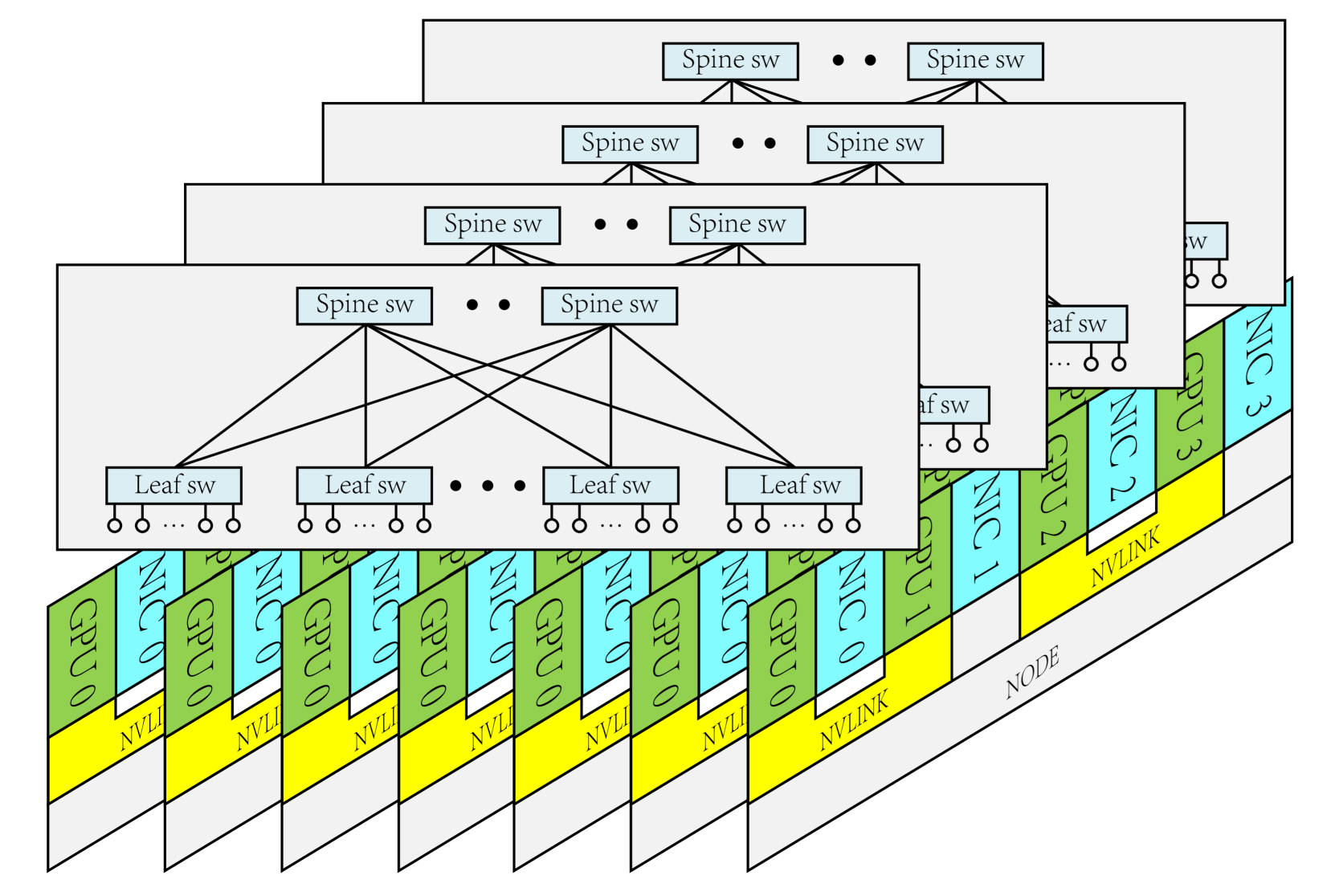
(Image from [4])
Performance
On the GitHub page [2], 3FS announced that its read stress test achieved a throughput of 6.6 TB/s. The cluster has 180 storage nodes, each equipped with 16 14 TB NVMe SSDs. This means that the average throughput per SSD is 2.3 GB/s, and 3FS has nearly achieved the native performance of hardware flash storage.

(Image from [2])
The DeepSeek infrastructure paper [4] contains more detailed hardware configurations. Note that the 3FS client runs on GPU nodes, which are responsible for the heavy LLM training and inference, have high resource demands, and need to avoid interference from clients.

References and Materials
[1] Summary of LLM-Price large language model service prices: https://github.com/syaoranwe/LLM-Price
[2] DeepSeek 3FS : https://github.com/deepseek-ai/3FS/blob/main/docs/design_notes.md
[3] DeepSeek 3FS blog : https://www.high-flyer.cn/blog/3fs/
[4] DeepSeek AI infrastructure paper 2024 : https://arxiv.org/html/2408.14158v1
[5] P Specifications in 3FS : https://github.com/deepseek-ai/3FS/blob/main/specs/README.md
[6] Industrial Use of TLA+ : https://lamport.azurewebsites.net/tla/industrial-use.html
[7] P Spec case studies : https://p-org.github.io/P/casestudies/
[8] P Spec search prioritization heuristics : https://ankushdesai.github.io/assets/papers/fse-desai.pdf
[9] P Spec in Microsoft USB3 : https://www.microsoft.com/en-us/research/blog/p-programming-language-asynchrony/
[10] P Specification in Microsoft IoT : https://www.infoworld.com/article/2250253/microsoft-open-sources-p-language-for-iot.html
[11] P Specification in Microsoft Async Event Handling : https://www.microsoft.com/en-us/research/project/safe-asynchronous-programming-p-p/
[12] TLA+ at AWS : https://lamport.azurewebsites.net/tla/formal-methods-amazon.pdf
[13] TLA+ at AWS S3 : https://www.amazon.science/publications/using-lightweight-formal-methods-to-validate-a-key-value-storage-node-in-amazon-s3
[14] TLA+ in MongoDB Replication Protocols : https://www.mongodb.com/community/forums/t/about-the-tla-specifications-of-mongodb/275204
[15] TLA+在TiDB中 : https://github.com/pingcap/tla-plus
[16] TLA+在CockroachDB中 : https://github.com/cockroachdb/cockroach/blob/master/docs/tla-plus/ParallelCommits/ParallelCommits.tla
[17] 3FS uses Rust to build its storage engine : https://github.com/deepseek-ai/3FS/tree/main/src/storage/chunk_engine
[18] Rust to rewrite the Linux Kernel : https://www.usenix.org/conference/atc24/presentation/li-hongyu
[19] HopsFS paper 2017 : https://www.usenix.org/conference/fast17/technical-sessions/presentation/niazi
[20] Facebook (Meta) Tectonic : https://www.usenix.org/conference/fast21/presentation/pan
[21] Apple FoundationDB : https://www.foundationdb.org/files/fdb-paper.pdf
[22] Apple FoundationDB Github : https://github.com/apple/foundationdb
[23] Ceph BlueStore using RocksDB : https://docs.ceph.com/en/reef/rados/configuration/bluestore-config-ref/
[24] JuiceFS metadata engine selection : https://juicefs.com/en/blog/usage-tips/juicefs-metadata-engine-selection-guide
[25] 3FS USRBIO API : https://github.com/deepseek-ai/3FS/blob/main/src/lib/api/UsrbIo.md
[26] DeepSeek 3FS Source Code Interpretation - Disk IO Section : https://zhuanlan.zhihu.com/p/27497578911
[27] Raft in TiDB : https://www.vldb.org/pvldb/vol13/p3072-huang.pdf
[28] Raft in PolarFS : https://zhuanlan.zhihu.com/p/653252230
[29] Diving Deep on S3 Consistency : https://www.allthingsdistributed.com/2021/04/s3-strong-consistency.html
[30] Azure Storage paper 2011 : https://azure.microsoft.com/en-us/blog/sosp-paper-windows-azure-storage-a-highly-available-cloud-storage-service-with-strong-consistency/
[31] Ceph unified storage : https://ceph.io/en/
[32] VAST DATA Whitepaper : https://www.vastdata.com/whitepaper/
[33] 3FS to generate chain table when deploying : https://github.com/deepseek-ai/3FS/blob/main/deploy/data_placement/README.md
[34] Google Orion SDN paper 2021 : https://www.usenix.org/conference/nsdi21/presentation/ferguson
[35] Redhat introduction to io_uring : https://developers.redhat.com/articles/2023/04/12/why-you-should-use-iouring-network-io